speeding up diffusion models with first block caching
inference speed and quality is all you need from a diffusion model and one of the simplest but very effective optimization techniques is something called “first block caching” that can significantly speed up inference with minimal quality loss.
the main idea
the idea behind first block caching is dead simple: not every timestep in a diffusion model’s denoising process requires the same amount of computation. some steps produce large changes to the latent representation, while others make only minor adjustments. by detecting when a timestep will produce minimal changes, we can skip most of the computation for that step.
this technique builds on principles from the TEACache paper and the ParaAttention repository implements a related but distinct approach called “first block caching”.
tl;dr: instead of predicting output differences from timestep embeddings, it computes the first portion of the network and uses that intermediate result to decide whether to continue or reuse cached outputs.
how it works?
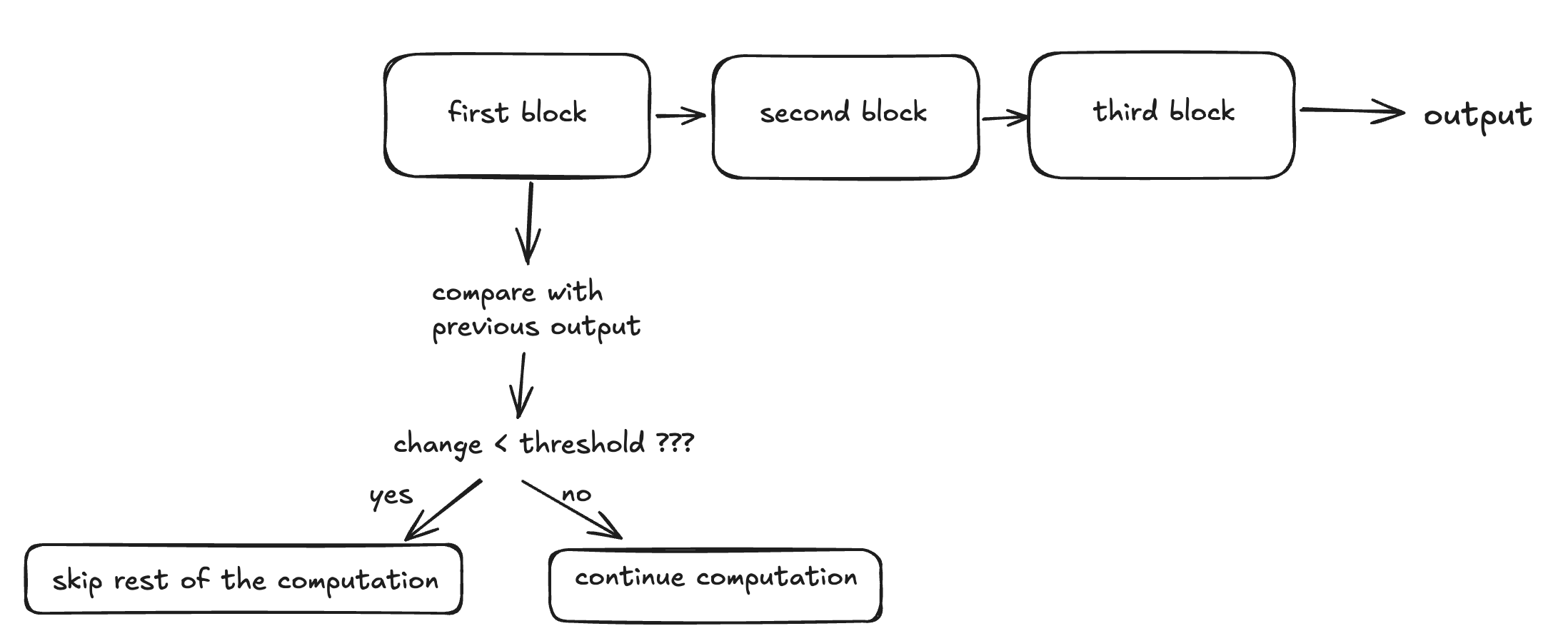
it operates on a simple but powerful principle:
- divide the model into blocks - the neural network’s forward pass is split into sequential blocks
- run the first block - execute only the initial portion of the network
- compare outputs - check how much the intermediate representation changed compared to the previous timestep
- make a decision - if the change is below a threshold, skip the remaining blocks and reuse cached results
some visual representation of the process:
memory and computation
how this caching may affect memory and computation over time hypothetically:
Memory Usage Pattern:
┌─────────────────────────────────────────────────────┐
│ GPU Memory │
│ ▓▓▓▓▓▓▓ Base Model │
│ ░░░ First Block Output Cache (small) │
│ ▒▒▒ Final Output Cache (medium) │
│ │
│ Normal Forward Pass: │
│ ▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓ Full computation │
│ │
│ Cached Forward Pass: │
│ ▓▓▓░░ First block + cache lookup │
│ │
└─────────────────────────────────────────────────────┘
Computation Time Comparison:
┌─────────────────────────────────────────────────────┐
│ Timesteps: 1 2 3 4 5 6 7 8 9 10 11 12 │
│ │
│ Without Caching: │
│ ████ ████ ████ ████ ████ ████ ████ ████ ████ ████ │
│ │
│ With Caching (42% hit rate): │
│ ████ ████ █ ████ █ █ ████ █ ████ █ ████ █ │
│ │
│ Legend: ████ = Full computation │
│ █ = Cached computation │
└─────────────────────────────────────────────────────┘
minimal implementation with pytorch
first, we’ll create a basic caching mechanism with pure pytorch:
import torch
import torch.nn as nn
from typing import Optional, Dict, Any
class FirstBlockCache:
def __init__(self, threshold: float = 0.12):
self.threshold = threshold
self.previous_first_block_output: Optional[torch.Tensor] = None
self.cached_final_output: Optional[torch.Tensor] = None
self.cache_hits = 0
self.total_calls = 0
def should_skip_computation(self, current_output: torch.Tensor) -> bool:
"""deciding if we should skip the rest of the forward pass."""
if self.previous_first_block_output is None:
self.previous_first_block_output = current_output.clone()
return False
# relative change between current and previous outputs
diff = torch.norm(current_output - self.previous_first_block_output)
relative_diff = diff / (torch.norm(self.previous_first_block_output) + 1e-8)
self.previous_first_block_output = current_output.clone()
if relative_diff < self.threshold:
self.cache_hits += 1
return True
return False
def update_cache(self, output: torch.Tensor):
self.cached_final_output = output.clone()
def get_cached_output(self) -> torch.Tensor:
if self.cached_final_output is None:
raise ValueError("No cached output available")
return self.cached_final_output
def get_cache_stats(self) -> Dict[str, float]:
hit_rate = self.cache_hits / max(self.total_calls, 1)
return {
"cache_hits": self.cache_hits,
"total_calls": self.total_calls,
"hit_rate": hit_rate
}
integrating this into a simplified diffusion model structure:
class OptimizedDiffusionBlock(nn.Module):
def __init__(self, model: nn.Module, cache_threshold: float = 0.12):
super().__init__()
self.model = model
self.cache = FirstBlockCache(cache_threshold)
# we need to identify where the "first block" ends
self.first_block_layers = self._extract_first_block()
self.remaining_layers = self._extract_remaining_layers()
def _extract_first_block(self) -> nn.Module:
"""extracting the first block of layers from the model."""
layers = list(self.model.children())
first_block_size = len(layers) // 4 # using first 25% as "first block"
return nn.Sequential(*layers[:first_block_size])
def _extract_remaining_layers(self) -> nn.Module:
layers = list(self.model.children())
if len(layers) == 0:
return nn.Identity()
first_block_size = len(layers) // 4
return nn.Sequential(*layers[first_block_size:])
def forward(self, x: torch.Tensor) -> torch.Tensor:
self.cache.total_calls += 1
first_block_output = self.first_block_layers(x)
# can we skip the rest??
if self.cache.should_skip_computation(first_block_output):
return self.cache.get_cached_output()
final_output = self.remaining_layers(first_block_output)
self.cache.update_cache(final_output)
return final_output
for integration with libraries like diffusers:
from diffusers import FluxPipeline
import torch
def apply_first_block_caching(pipe: FluxPipeline, threshold: float = 0.12):
"""applying the first block caching to a Flux pipeline."""
original_unet = pipe.transformer
class CachedTransformer(nn.Module):
def __init__(self, original_model, cache_threshold):
super().__init__()
self.original_model = original_model
self.cache = FirstBlockCache(cache_threshold)
def forward(self, *args, **kwargs):
return self._cached_forward(*args, **kwargs)
def _cached_forward(self, hidden_states, *args, **kwargs):
self.cache.total_calls += 1
# for FLUX, we'd need to identify the first transformer block
# assuming we can get first block output somehow
first_block_output = self._compute_first_block(hidden_states, *args, **kwargs)
if self.cache.should_skip_computation(first_block_output):
return self.cache.get_cached_output()
full_output = self.original_model(hidden_states, *args, **kwargs)
self.cache.update_cache(full_output)
return full_output
def _compute_first_block(self, hidden_states, *args, **kwargs):
with torch.no_grad():
# run a subset of the transformer layers
return hidden_states
pipe.transformer = CachedTransformer(original_unet, threshold)
return pipe
# example usage would be like:
pipe = FluxPipeline.from_pretrained("black-forest-labs/FLUX.1-dev")
pipe = apply_first_block_caching(pipe, residual_diff_threshold=0.12)